Implementing Data Contracts
Data contracts help you document and enforce the shape and metadata of your records through data pipelines and processing systems. Their main goal is reducing surprises and getting rid of undocumented changes.
For example, if data producers and data consumers agree that the data interchanged between them has a specific schema, this can (and should) be verified for every message.
If the schema changes on the producer side and the consumers are not aware of this, they will very quickly fall apart, so it’s essential that these contracts are stored somewhere and upheld by both sides with automated verification checks.
All the code snippets mentioned in the article are available in this repository.
Theory
There are many ways actually to define this contract between data producers & consumers. Kafka for example has an excellent tool for this, called the Schema Registry.
Your primary pipeline without any contracts can look something like this
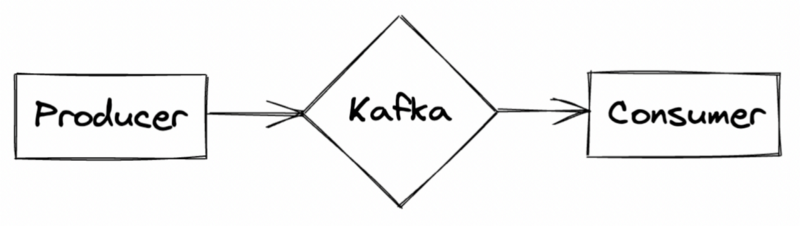
The producer application is free to push data into Kafka, and the consumer will read all incoming data from this topic. You can imagine the case when for some reason (that can be a change in the business logic or a change in the source data that the producer uses), the message schema changes; there is no way for the consumer to know about these changes before the data actually gets to it.
Enter Schema Registry
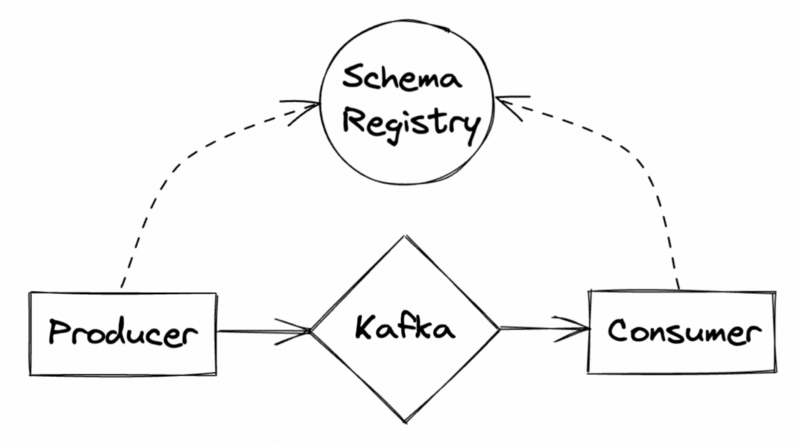
The Schema Registry is a separate process that lives outside the cluster and is used by both the producer and consumer concurrently to push/consume messages from Kafka.
The Schema Registry stores and serves metadata for your messages. The schemas are versioned, and the registry also provides various compatibility settings which enable schema evolution for messages.
You can read more about the idea behind data contracts on various other blogs. This post will focus on a very minimal implementation for those of us who learn better this way.
Implementation
Let’s implement our data contract-less example first to showcase the drift situation.
We can quickly spin up a Confluent cluster combining their great Docker images with docker-compose
No Zookeeper 👀, yay!
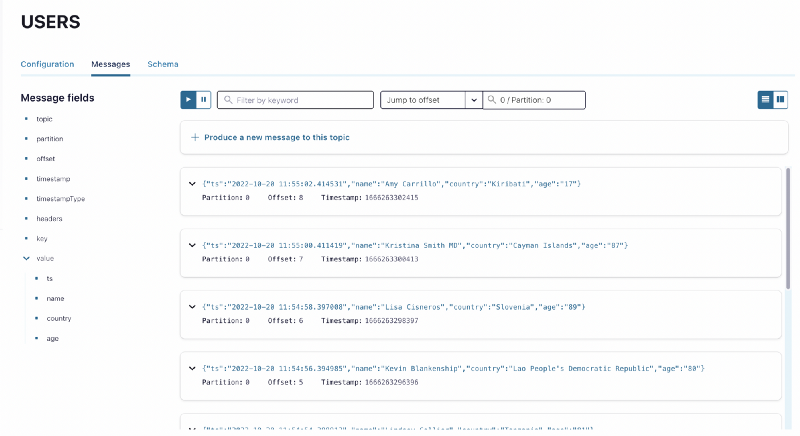
Next, let’s produce some fake User data into a topic called USERS .
After our Kafka cluster is alive, we can start producing data by running the above script:python producer.py.
We can look at the included Control Center (accessible at localhost:9021) to verify that data is indeed getting pushed into our target topic.
Now, downstream a consumer might look something like this:
This basic consumer will read the messages that arrive in the USERS topic and calculate the average age of all the users that it has seen and print them out to the terminal like this:{'ts': '2022-10-20 11:54:46.362432', 'name': 'Michael Hunt', 'country': 'Belgium', 'age': '40'} | Average age: 40 | User count: 1{'ts': '2022-10-20 11:54:48.367588', 'name': 'Sergio Williams', 'country': 'Greece', 'age': '49'} | Average age: 44 | User count: 2{'ts': '2022-10-20 11:54:50.372057', 'name': 'Mrs. Mary Davidson PhD', 'country': "Lao People's Democratic Republic", 'age': '54'} | Average age: 47 | User count: 3
Now let’s say the producer introduces a change in the schema. The imaginary source service decided to give us the Date of Birth for each user instead of their age, and now our producer will look like this:
Kafka has no issue storing this data with the new schema in the same topic, as we can verify in the Control Center.
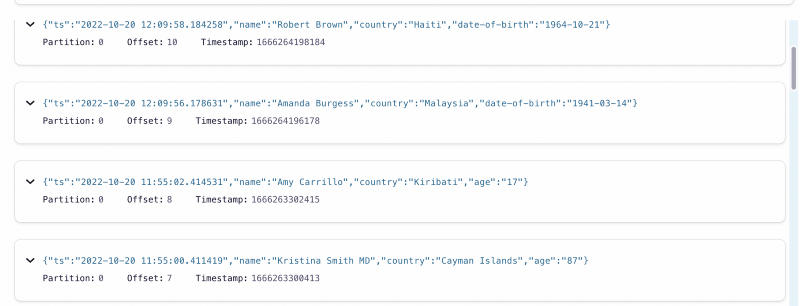
But if we run our consumer we are going to run into trouble.Traceback (most recent call last):
File "/Users/daniel.palma/Personal/data-contracts-kafka/consumer/main.py", line 34, in <module>
consume_messages()
File "/Users/daniel.palma/Personal/data-contracts-kafka/consumer/main.py", line 25, in consume_messages
average_age = (average_age * user_count + int(value["age"])) // (user_count + 1)
KeyError: 'age'
Of course, the new records don’t have the age key so our service fails. Thankfully, we know what happened on the producer side but imagine a large organization with hundreds and thousands of producers and consumers, where the teams responsible for these applications are simply moving at too different paces to be able to notify every downstream consumer about changes like this manually.
Now you have two options here:
- Figure out what changed, update the consumer, restart the service and wait for this to happen again.
- Implement a contract between the producer and the consumer that will catch changes like this early allowing you to prepare for schema evolutions like this.
The first option is easy to implement (assuming you can decipher the issue by yourself!) but not very future-proof as these things happen all the time.
The second option forces both parties to agree on a schema that will be used and allows the system to enforce it even before the producer pushes data to Kafka!
Catching the change this early can guarantee that the downstream consumers will know about the schema evolution as there is no way for the producer to continue with the new schema without actually updating the Schema Registry, where our contracts are stored — and updating the contract is not possible without both parties agreeing to it.
Enter Schema Registry
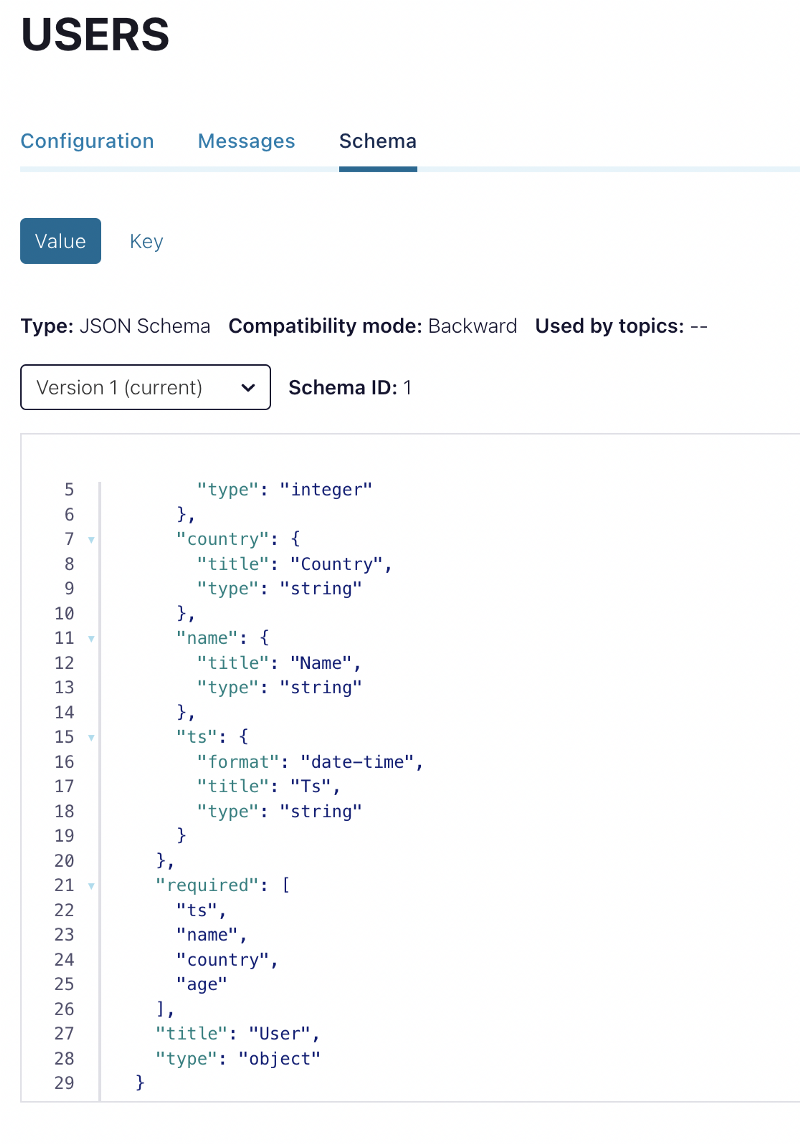
Let’s register our initial schema in the Schema Registry with the following snippet
Pydantic and python-schema-registry-client are two great libraries that can help us out here. As you can see we assign the schema to the value of the USERS topic, based on the subject naming strategy that we chose.
To verify, we can check the Control Center again:
Now just need to refactor our producer a little to include a compatibility check before sending out a message.
We simply grab the latest version of the schema and compare it to the schema of the data that we are going to send. In our case the test will pass as the schema we registered above is exactly the same as the one we are pushing here.
On the consumer side, we can do the same thing and validate the schema of the incoming message and fail fast if something unexpected is coming down the pipe.
Now if we were to change our producer model to send the Date of Birth instead of the age like this
Our compatibility check would fail instantly and raise an exceptionException: Schema is not compatible with the latest version
This is exactly what we want! Enforcing checks like this makes the collaboration between producer and consumer easier because they can both rest assured that what they expect is going to happen. The fewer surprises the better.
For the record, these validations can be enforced on the topic level in Kafka, but the point of this exercise is to show a more general idea of data contracts, not something Kafka-specific.
The process to update a contract would be to register the new version of the schema in the Schema Registry which forces us to create a public (and reviewable!) update which can be discussed and if agreed on — followed up on the consumer side.
Data Contracts can include anything in them, the only assumption is that both parties agree (and enforce!) their content.
Storing the contracts separately allows our architecture to reuse them in different places, which increases our flexibility while exponentially reducing the number of possible surprises as the number of contract users increases.
Value (is there any?)
All the talk around data contracts in theory makes it hard to actually see how they can provide value but if we focus on the issue that it’s supposed to solve we can quickly see how useful they are.
Also, this example uses a basic Kafka setup in the middle because I have only seen abstract articles about the topic so far or implementations on huge systems so I thought starting with a minimal implementation would be helpful in seeing how the whole thing can help us in the long run.
Member discussion