Data Ingestion for Snowflake ❄️

Data ingestion is a critical step in the data processing pipeline, and Snowflake, a leading cloud-based data warehousing platform, offers a plethora of options for ingesting data.
In this technical blog post, I'll delve into the complexities of Snowflake's data ingestion strategies, exploring different use cases and dissecting the trade-offs between various methods.
Specifically, I'll focus on the COPY function, serverless ingests with Snowpipe and integration with Kafka for streaming data. By dissecting these strategies, I aim to provide readers with a deep understanding of how to optimize data ingestion while maintaining cost-effectiveness and efficiency.
Use Case Classification for Enhanced Intuition
When faced with numerous data ingestion options, classification based on use cases can provide a more intuitive approach. Snowflake's extensive capabilities span different scenarios, and by classifying use cases, we can identify optimal ingestion methods. Our primary focus in this discussion is the bulk load process using COPY, serverless ingest with Snowpipe, and integration with Kafka for streaming data.
Keeping this in mind, let's start by taking a look at the most common tool used to move data into Snowflake.
Bulk Import Strategy with COPY
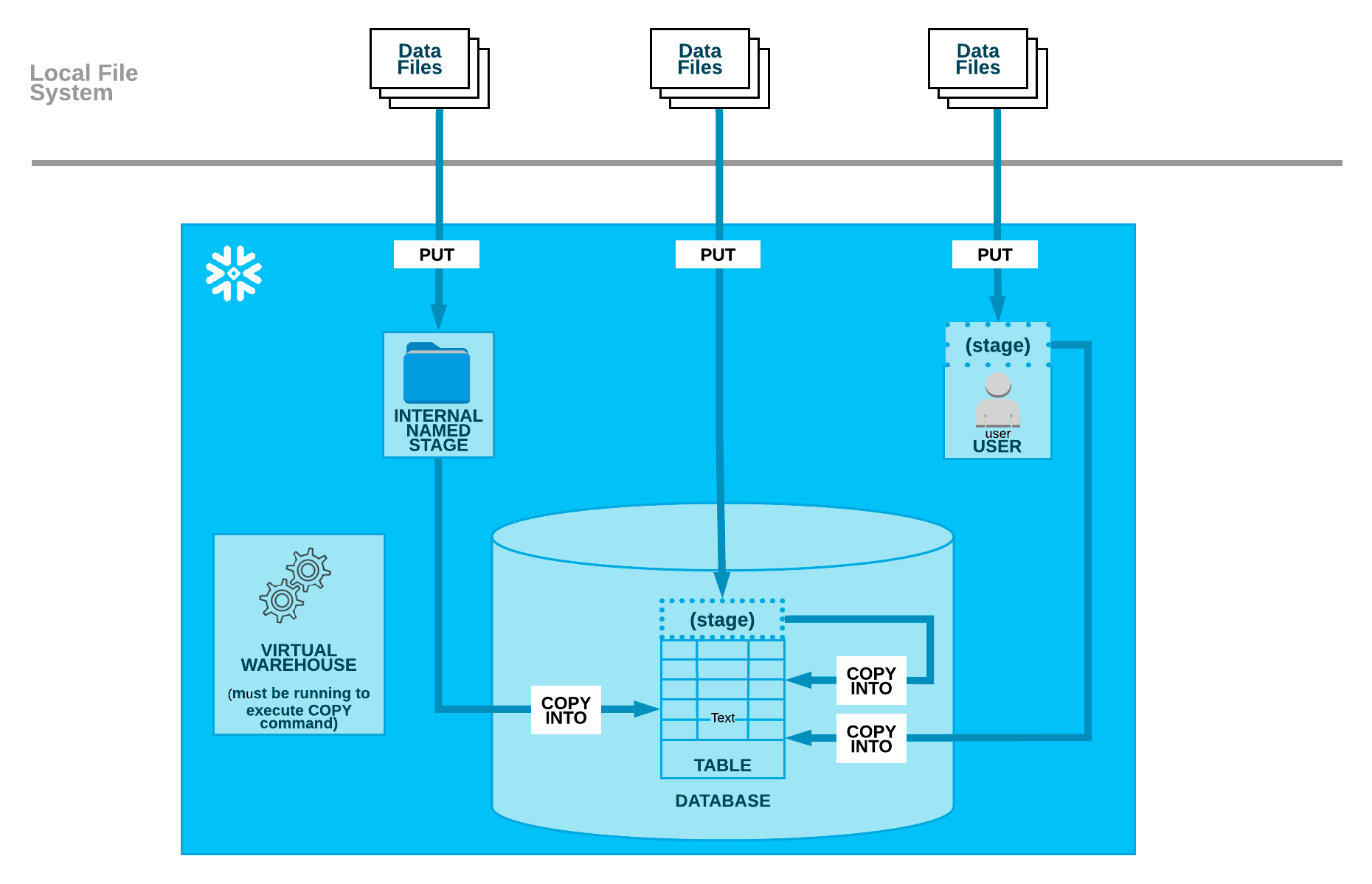
The bulk import strategy involves utilizing Snowflake's COPY command to load data into the platform. While straightforward, this approach can lead to inefficiencies, especially when dealing with underutilized warehouses. The average cost of data ingested can be prohibitively high due to the constant idle state of the warehouse waiting for periodic data uploads. However, optimizing concurrency and file sizes can mitigate these challenges.
Here's how it could look to set up an ingestion pipeline with COPY:
-- Creating an external stage
CREATE OR REPLACE STAGE my_stage
URL = 's3://my-bucket/path'
CREDENTIALS = (AWS_KEY_ID = 'your_key_id' AWS_SECRET_KEY = 'your_secret_key');
-- Copy data from the external stage into a table
COPY INTO my_table
FROM @my_stage/data.csv
FILE_FORMAT = (TYPE = CSV);
-- Check the copy history
SELECT *
FROM TABLE(INFORMATION_SCHEMA.COPY_HISTORY(TABLE_NAME => 'my_table'));
- The first step is to create an external stage, which is a reference to the location of your data in a cloud storage service like Amazon S3.
- The
COPY INTOcommand is used to copy data from the external stage into a Snowflake table. - The
FILE_FORMATspecifies the format of the files in the stage (e.g., CSV). - The final query checks the copy history to monitor the status of the copy operation.
Optimizing COPY-based ingestion
When utilizing Snowflake's COPY command for batch data loading, you have two main avenues to optimize cost and performance. One is to make sure files being ingested conform to the recommended file size range and the other option is switching to a serverless ingestion workflow with Tasks.
Let's dive a bit into how we can make this process less wasteful!
File-size optimizations
When utilizing Snowflake's COPY command for batch data loading, one of the most significant factors influencing performance is the size of the input files. Achieving optimal COPY performance is intricately tied to preparing files within a specific size range, typically between 100 to 250 megabytes. This range ensures efficient utilization of Snowflake's underlying architecture and minimizes processing overhead.
The reason behind this emphasis on file size lies in Snowflake's data-loading mechanism. The COPY command is designed to work efficiently with files that are well-sized, allowing for seamless parallelization and optimized resource allocation. When files fall within the 100 to 250-megabyte range, Snowflake's processing capabilities are harnessed to their fullest potential, resulting in faster data ingestion and query performance.
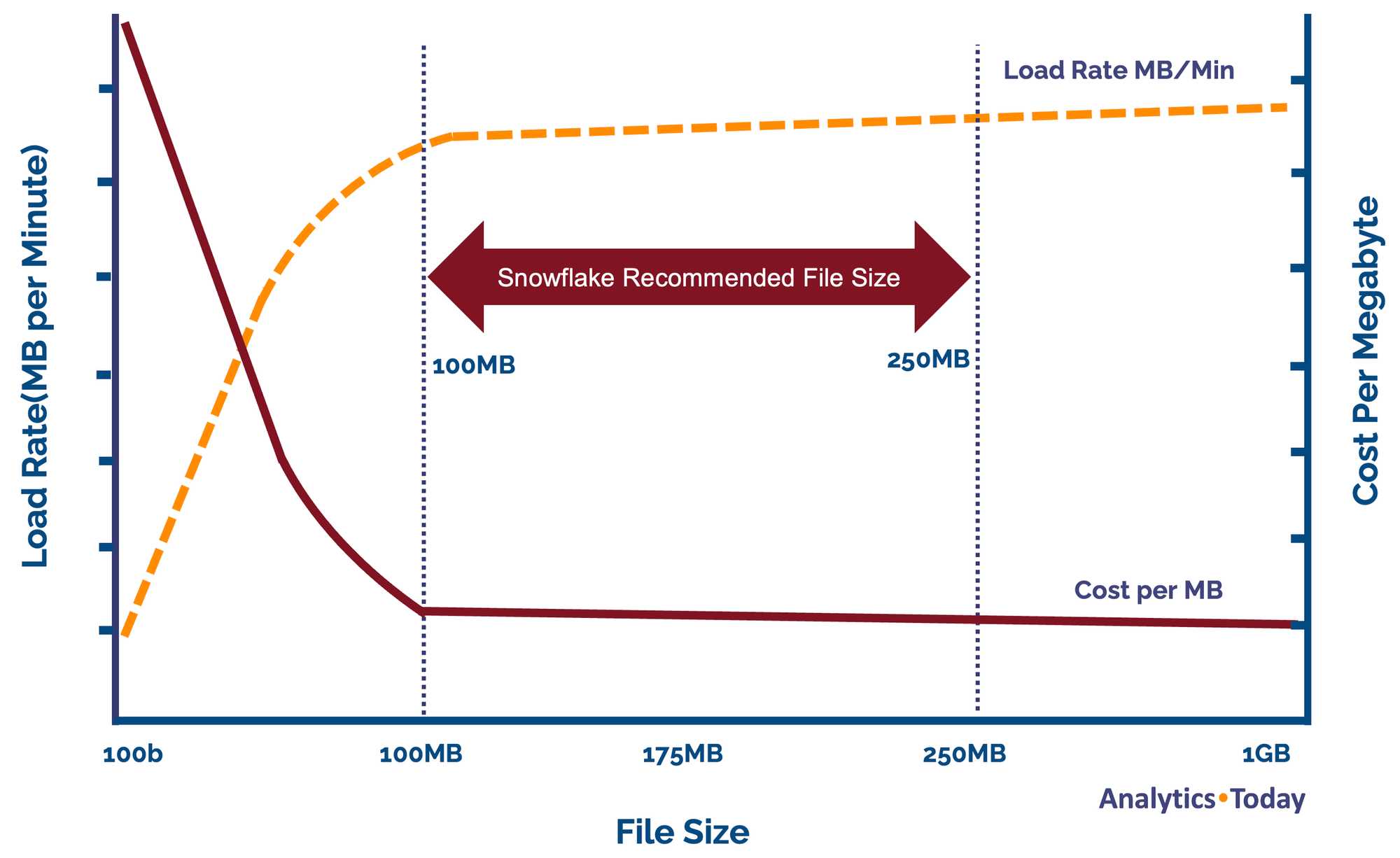
However, achieving perfectly sized files isn't always feasible, especially when dealing with diverse data sources or unpredictable data generation patterns. In such cases, it's important to consider whether the COPY command remains the appropriate choice. While COPY excels in scenarios where well-sized files are readily available, its efficiency diminishes when dealing with files significantly smaller or larger than the optimal range.
For organizations unable to consistently prepare files within the recommended size range, alternative data loading methods, such as Snowpipe streaming, may offer more suitable solutions. Snowpipe's real-time data ingestion capabilities reduce the reliance on achieving perfectly sized files, making it a preferable option for scenarios where file size optimization is challenging. We'll talk more about Snowpipe a bit later, hang tight!
Serverless COPY using Tasks
A Task is a predefined unit of work that encapsulates a set of SQL statements or other operations. It serves as a mechanism for automating routine data processing tasks, such as data transformation, loading, or maintenance. By defining Tasks, users can efficiently manage and schedule complex data workflows without manual intervention.
Tasks can be triggered based on various events, such as time schedules or data availability, making them a crucial component for orchestrating data pipelines and ensuring streamlined, automated data processing within the Snowflake environment.
-- Creating a serverless task to copy data
CREATE OR REPLACE TASK copy_task
SCHEDULE = 'USING TIMESTAMP ADD MINUTES(1)'
AS
COPY INTO my_table FROM @my_stage/data.csv FILE_FORMAT = (TYPE = CSV);
-- Check the task status
SHOW TASKS LIKE 'copy_task';- A serverless task is created using the
CREATE OR REPLACE TASKcommand. The task is scheduled to run at specified intervals. Note that we omit theWAREHOUSEparameter, which will allow Snowflake to manage the compute resources required in a serverless manner. Add aCOPYoperation to the task, which copies data from the stage to the table. - The status of the task can be checked using the
SHOW TASKScommand.
For organizations seeking to optimize data ingestion costs and streamline their processes, switching to serverless ingestion using Snowflake Tasks can offer a cost-effective and efficient solution. The transition to serverless ingestion involves leveraging Snowflake's serverless compute resources to perform data-loading tasks, such as the COPY command, in a more dynamic and responsive manner. This approach eliminates the need for continuously provisioned resources and offers significant cost savings, especially in scenarios where workloads vary over time.
Switching to serverless ingestion using Snowflake Tasks offers a flexible and cost-effective approach to data loading. By embracing this method, organizations can optimize their data pipelines, reduce costs, and better align their resources with actual workload demands.
Serverless Ingest with Snowpipe
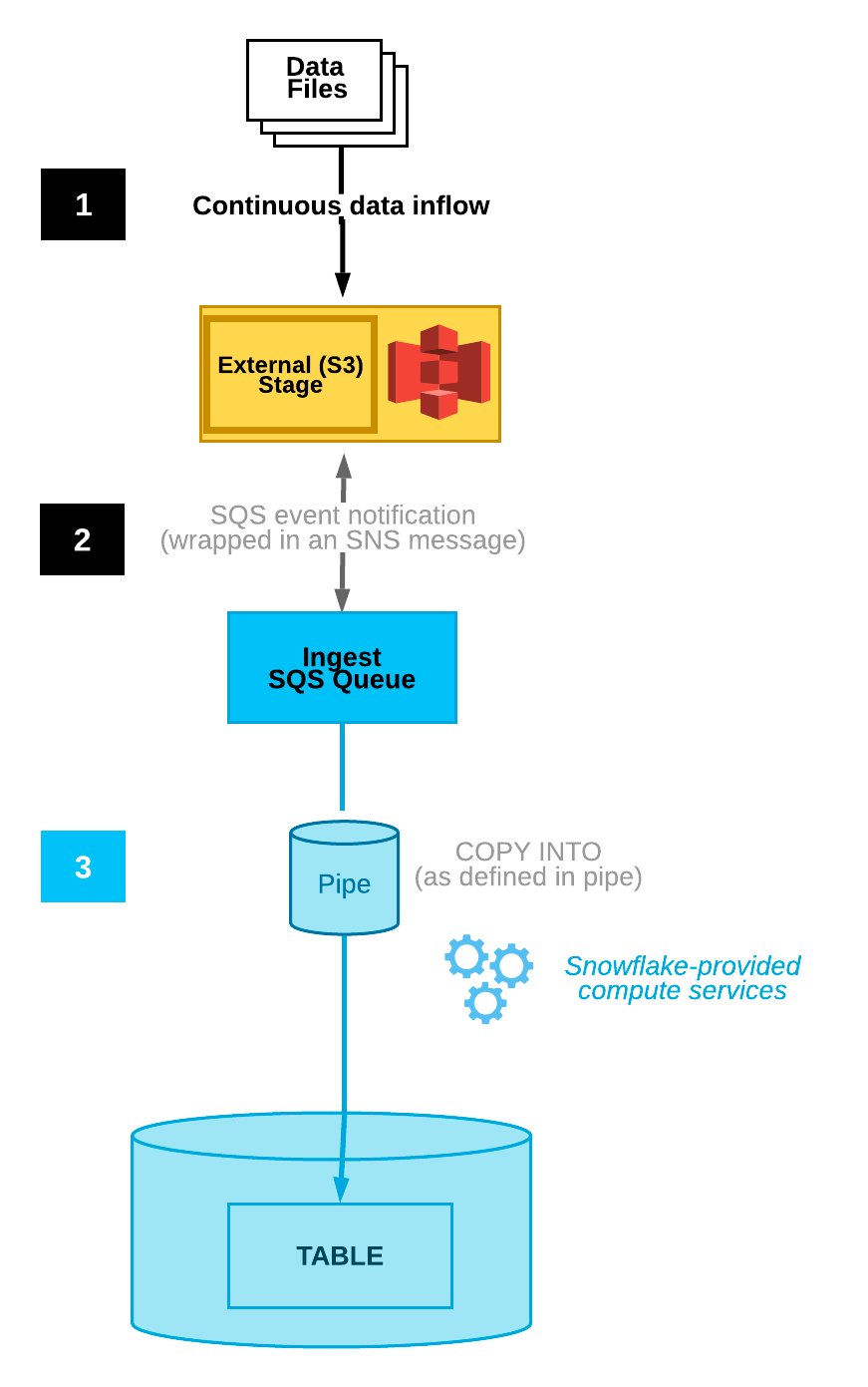
Serverless ingest via Snowpipe addresses the limitations of the copy insert strategy by introducing dynamic, on-demand ingestion. Leveraging serverless tasks and Snowpipe, data is ingested as it arrives, eliminating the need for constant warehouse usage. By using a serverless task to perform the copy insert, concurrency is optimized, significantly reducing costs. Additionally, serverless ingest eliminates the need for manual intervention, making it a powerful and efficient solution.
Recognizing the limitations of the COPY INTO approach, Snowflake introduced the Snowpipe Batch Solution, a serverless ingestion mechanism designed to streamline the data loading process and optimize warehouse usage. The Snowpipe Batch Solution leverages the serverless architecture of Snowflake and employs tasks for optimized data ingestion. By replacing the manual COPY INTO process with automated serverless tasks, this approach significantly reduces latency, improves efficiency, and minimizes costs.
-- Creating a pipe
CREATE OR REPLACE PIPE my_pipe
AUTO_INGEST = TRUE
AS
COPY INTO my_table
FROM @my_stage/data.csv
FILE_FORMAT = (TYPE = CSV);
-- Check the pipe status
SHOW PIPES LIKE 'my_pipe';
-- Monitor pipe history
SELECT *
FROM TABLE(INFORMATION_SCHEMA.PIPE_HISTORY(PIPE_NAME => 'my_pipe'));
- A Snowpipe is a continuous data ingestion feature that automatically loads new data from a stage into a table as soon as it arrives.
- The
CREATE OR REPLACE PIPEcommand creates a pipe and specifies the table to load data into, along with the source stage and file format. - The
AUTO_INGEST = TRUEsetting ensures that new data is automatically ingested into the table. - The pipe status and history can be monitored using the
SHOW PIPESandINFORMATION_SCHEMA.PIPE_HISTORYcommands.
How Snowpipe Batch Works
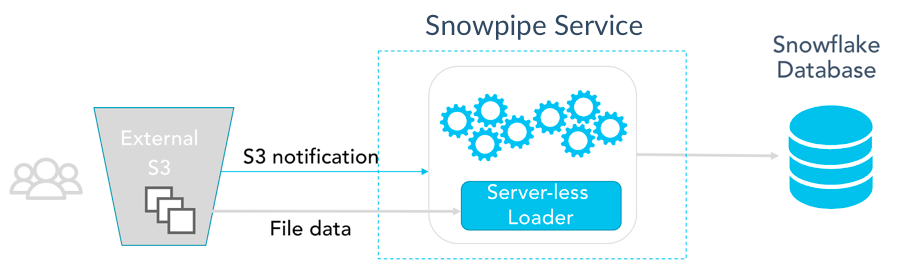
- Staging and Automation: Data files are staged in cloud storage, and Snowpipe monitors the staging area for new data.
- Serverless Tasks: Snowpipe uses serverless tasks behind the scenes to automate the data ingestion process. The serverless task handles the copying of data from the staging area into Snowflake tables.
- Efficient Batching: Snowpipe employs micro-batching techniques to process and load small batches of data efficiently in parallel. This reduces overhead and enhances performance.
- Optimized Cost: Since serverless tasks are billed by execution time – as opposed to active warehouse time – costs are minimized by only consuming resources when needed.
Advantages of Snowpipe Auto-Batch Solution
- Reduced Latency: Snowpipe's serverless ingestion minimizes latency by automating data ingestion and optimizing the loading process.
- Optimized Cost: The serverless nature of Snowpipe ensures efficient resource utilization and reduces unnecessary costs associated with underutilized warehouses.
- Simplicity and Automation: Snowpipe's automated tasks eliminate the need for manual intervention, enhancing ease of use and operational efficiency.
- Scalability: Snowpipe scales seamlessly to accommodate varying data volumes and workloads, ensuring consistent performance during peak times.
Implementation and Considerations
Transitioning to the Snowpipe Auto-Batch method from serverless COPY commands via tasks involve configuring a staging area in cloud storage, creating pipes, and optimizing the incoming file's size and structure.
Keep in mind that Snowpipe doesn't guarantee the order of the files being ingested due to its async nature.
Comparing Snowpipe Auto-Batch with Other Approaches
To contextualize the benefits of the Snowpipe Auto-Batch Solution, a comparative analysis was conducted using a data generator mimicking a real-world use case of a ski resort ticketing system. The traditional COPY INTO method exhibited inefficiencies due to underutilization, resulting in high costs per ingested megabyte.
In contrast, the Snowpipe Auto-Batch Solution demonstrated significant improvements in cost, credit consumption, and visibility time. By adopting Snowpipe's serverless ingestion, organizations can effectively optimize their data-loading workflows and realize substantial cost savings.
Kafka Integration for Streaming Data
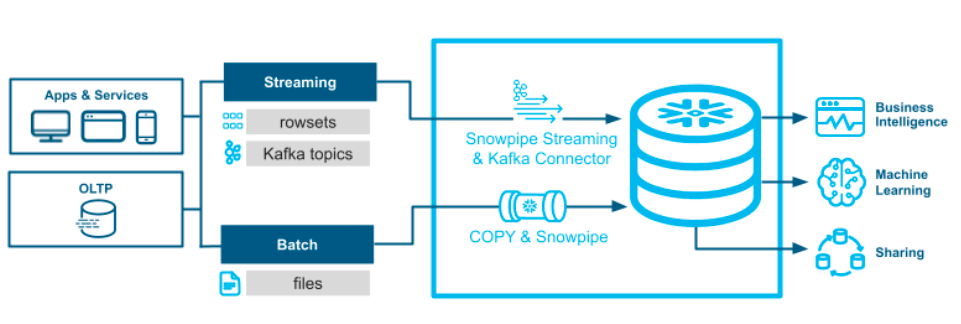
Snowflake's integration with Kafka opens doors to real-time streaming data ingestion. The traditional batch mode, where data accumulates before ingestion, is enhanced by the streaming SDK within Kafka connectors. This upgrade allows for faster visibility, reducing latency and facilitating sub-second query times. The integration caters to various Kafka versions and offers columnarization options, streamlining data transformations, meaning the incoming data can be automatically split into separate columns, sparing you from having to mangle JSONs.
Kafka Snowpipe Streaming emerges as a powerful solution to the challenges posed by batch processing. By leveraging Kafka's capabilities and integrating with Snowflake, this method enables seamless, real-time data ingestion. The integration of Snowpipe Streaming with Kafka brings unprecedented efficiency to the data ingestion process.
The API is currently limited to inserting rows. To modify, delete, or combine data, write the “raw” records to one or more staging tables. Merge, join, or transform the data using continuous data pipelines to insert modified data into destination reporting tables.
Key Features and Benefits
- Real-time Ingestion: With Kafka Snowpipe Streaming, data is ingested in real-time, minimizing latency and providing up-to-the-minute insights.
- Faster Visibility: Unlike traditional batch processing, where data visibility can be delayed, Snowpipe Streaming ensures near-instantaneous data availability, reducing the time to visibility significantly.
- Simplified Configuration: Snowpipe Streaming eliminates the need for complex configuration parameters, making the setup process streamlined and user-friendly.
- Efficient Utilization: Snowpipe Streaming's micro-batching approach allows for the ingestion of even small file sizes, ensuring efficient resource utilization and cost-effectiveness.
- Compatibility: The Kafka Snowpipe Streaming method is compatible with various Kafka versions and Kafka API-compatible services such as Redpanda, ensuring seamless integration into existing infrastructures.
The Streaming Workflow
The Snowpipe Streaming workflow involves a few key steps:
- Data Generation: Applications generate data in a streaming manner and push them into Kafka.
- Data Ingestion: Snowpipe Streaming allows data to be ingested directly from Kafka into Snowflake, reducing the need for intermediate storage and conversions.
- Efficient Transformation: The streaming SDK enables data to be columnarized and structured during ingestion, optimizing the process for further analysis.
- Data Availability: Data ingested via Snowpipe Streaming is made available for querying within seconds, making it an ideal choice for real-time analytics.
Comparative Analysis and Optimization
| Batch Ingestion via COPY | Serverless COPY via Tasks | Snowpipe Auto-Batch | Snowpipe Streaming | |
|---|---|---|---|---|
| Cost | High | Moderate | Moderate | Low |
| Input Throughput | Moderate | Moderate-High | High | High |
| Data Visibility | Delayed | Delayed | Moderate (mins) | Real-time (secs) |
Comparing these strategies reveals intriguing insights. Batch-based copy insert, while reliable, demands meticulous configuration to achieve optimal file sizes. Serverless ingest with Snowpipe simplifies the process by dynamically handling data, resulting in substantial cost savings and operational efficiency. Kafka integration empowers real-time streaming, with faster visibility and shorter query times, offering a compelling solution for certain use cases.
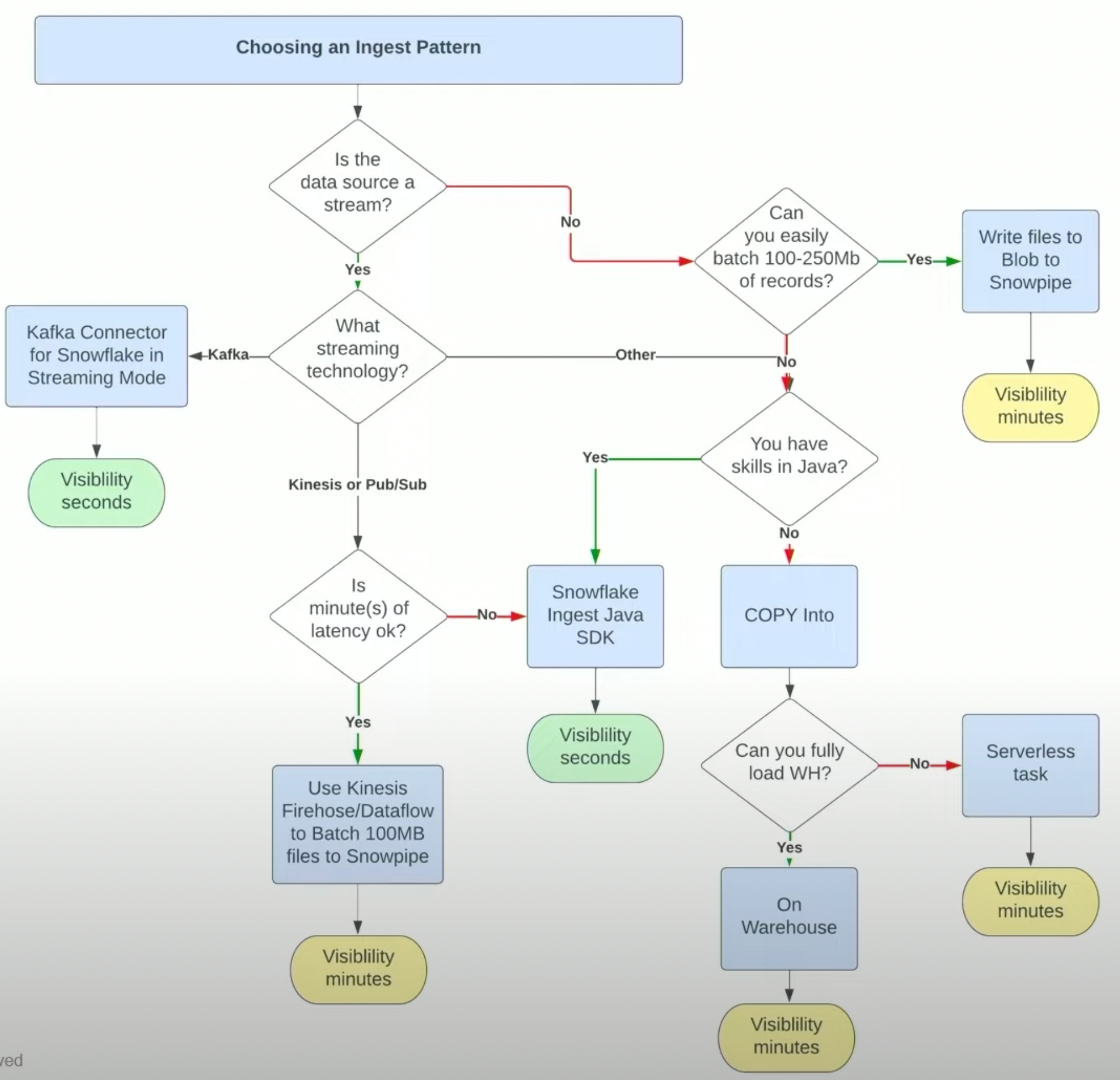
To get an idea about how to get evaluate which ingestion method is the one to choose for your use case, check out this great decision tree, from this talk – which inspired this blog post!
Conclusion
Data ingestion is a critical stage in any data analytics journey, and Snowflake's versatile strategies provide a range of options. Understanding the nuances of each method enables informed decision-making, ensuring data is ingested efficiently while managing costs. Whether it's the batch-based copy insert, the dynamic efficiency of serverless ingest via Snowpipe, or the real-time capabilities of Kafka integration, Snowflake equips organizations with tools to meet their diverse data ingestion needs. By selecting the right strategy for the right use case, organizations can optimize their data processing pipelines and unlock the true potential of their data.
Member discussion