Bit-sized data guides: Dimensional Modeling

If you work as a Data Engineer, Analyst, Scientist, Analytics Engineer, or pretty much anything in the data space, you have probably heard the term "dimensional modeling".
Dimensional modeling involves organizing data into easily understandable structures, emphasizing immutability for facts and the mutability of descriptive dimensions.
Here it is explained in 5 minutes.
Motivation
Imagine the following (fairly common) scenario: You have a bunch of data lying around and want to run some calculations on it.
After loading your data into a shiny analytical data warehouse to crunch the numbers, you realize – because of how your incoming data is structured – all of your analytical queries run into performance issues and you gotta start all of them by joining together 10 tables over some wild fields. Yuck!
To solve this, you decide to reorganize, or "model" your data inside your warehouse. The choices you make during this process will usually have more impact on your queries, than trying to optimize the SQL itself.
Dimensional modeling
Dimensional modeling is a classic (the concept is 40 years old!) way of organizing data that we will be discussing today. The basic idea behind this approach is to denormalize databases, making them more efficient than the typical OLTP for analytical processing.
In simple terms, dimensional modeling is about reorganizing your data into two main categories; facts & dimensions. This way, your fact tables contain all the data you want to aggregate or perform calculations on, which are your "facts" or similar to metrics.
On the other hand, dimension tables contain all the descriptive information such as customer name, account number, region, product, etc. Dimensions have a primary key that joins to a foreign key on a fact table, allowing you to query the descriptive dimensional values and numeric facts together.
Facts
As I mentioned, facts are quantifiable and aggregatable aspects of events. Using Uber as an example, the following facts can be identified which represent data collected by observing trips.
distance: The measurable distance covered during the ride.duration: The time taken for the entire ride.tip: An optional fact that represents additional financial information.wait_time: The duration between the ride request and the actual commencement of the trip.
This is how it would look in a database table:
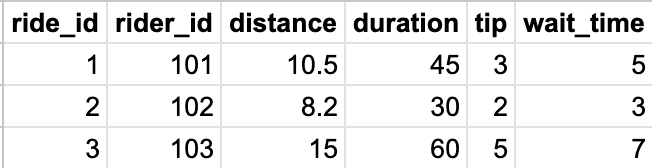
ride_fact tableDimensions
Dimension tables store descriptive information about business entities, providing context and details that enhance analytical insights when combined with fact tables in a data warehouse.
This rider_dimension table provides descriptive information about each rider, allowing for a deeper understanding of the individuals associated with Uber rides.
rider_idis a unique identifier for each rider.rider_namerepresents the name of the rider.phone_numbercontains the rider's contact number.emailholds the rider's email address.registration_dateindicates when the rider registered with Uber.
As a table:

rider_dimension tableExtra: Types of Dimensions
Dimensions can take on various forms in dimensional modeling:
- Slowly Changing Dimensions (SCD): These dimensions can change over time, such as the rider's phone number attached to their account. Handling such changes requires specific strategies to maintain historical accuracy.
- Conformed Dimensions: Dimensions like a calendar dimension table are consistent across multiple data sets, ensuring uniformity in reporting and analysis.
- Role-Playing Dimensions: Like a calendar table, a single dimension can play different roles in the model. For instance, it can be connected to both the start time and end time of the ride.
- Junk/Transaction Profile Dimension: This category serves as a catch-all for dimensions that don't fit neatly into other tables. Examples include the payment processor used or the route taken by the driver.
Conclusion
To create an effective dimensional model, you must first identify the level of detail of the event and differentiate between facts that can be aggregated and dimensions that cannot.
The example of Uber shows how dimensions and facts are interconnected to provide a complete understanding of business events. By adopting dimensional modeling, businesses can utilize their data to make informed decisions and gain a competitive advantage in the constantly evolving field of data analytics.
It's worth noting that dimensional modeling is not the only or the most efficient way to organize data for analytics. In case you want to explore other options, you can consider approaches like the "One Big Table" technique, Data Vaults, Star Schemas, or Snowflake Schemas, among others.
Member discussion