Where do Hungarians want to escape?

There is a subreddit called /r/escapehungary, which is dedicated to discussions about potential emigration destinations for Hungarians. Its inception was a direct consequence of last year's elections, where Fidesz – an authoritarian, right-wing party – extended its governing period by another 4 years.
As someone who recently left my home country, I wondered what potential destinations Hungarians are thinking about; so naturally, I dumped all the comments from the subreddit and started analyzing it!
The plan
The main question I want to be answered is the following:
What are the top countries that folks on the subreddit are discussing as potential destinations?
This will be a good starting point to familiarize yourself with the data and the tools required for the analysis.
So, on a very high level, these are the steps that I need to do:
- Get all text comments from the subreddit
- Extract country names from them
- Count how many times they appear
- ???
- Profit!
Easy, right? Well... there are a few issues. First, extracting country names is not that straightforward and we also need to consolidate them so we can aggregate the mentions!
We'll need some NLP magic for sure (I was debating using GPT for this, maybe in a different article!).
Let's dive in!
Getting the data
Reddit has an easily accessible API which made getting started not an issue. The target subreddit – being relatively new – has not had that much content generated so far, which meant I was okay using my own laptop for this project.
The first step was dumping everything on my machine so I wouldn't have to keep calling the Reddit API. This can be easily done with the following snippet:
def dump_subreddit(subreddit):
for submission in reddit.subreddit(subreddit).new(limit=None):
for comment in submission.comments:
created_at_utc = datetime.datetime.fromtimestamp(
comment.created_utc
).strftime("%Y-%m-%d")
# Create directory if it doesn't exist
os.makedirs(f"./data/{subreddit}/comments/{created_at_utc}", exist_ok=True)
with open(
f"./data/{subreddit}/comments/{created_at_utc}/{comment.id}.txt", "w"
) as f:
f.write(comment.body)This code downloads the comments and saves them as plaintext files in a directory structure partitioned by submission date.
This is what the result looks like on the filesystem:
data/escapehungary/comments master ❯ tree -L 2
.
├── 2022-04-04
│ ├── i3abdff.json
│ ├── i3abdff.txt
│ ├── i3acwoi.json
├── 2022-04-05
│ ├── i3f3dc7.json
│ ├── i3f3dc7.txt
│ ├── i3fhoi8.json
..Great we have a few comments to get started with.
data/escapehungary/comments master ❯ find . **/*.txt | wc -l
5916Entity extraction
Entity extraction (aka, named entity recognition or NER) is a type of NLP technology that helps us find important data in unstructured text. Entities can include names of people, places, organizations, and products, as well as dates, email addresses, and phone numbers.
The main function to do this looks like this:
def extract_location_entities(comment_text_file, backend="huspacy"):
comment_id = os.path.basename(comment_text_file).split(".")[0]
comment_date = os.path.basename(os.path.dirname(comment_text_file))
output_metadata_json_path = os.path.join(
os.path.dirname(comment_text_file), f"{comment_id}.json"
)
with open(os.path.join(comment_text_file), "r") as in_f:
text = in_f.read()
found_entities = find_entites(text, backend=backend)
print(f"Found: {found_entities} in comment {comment_id} on day {comment_date}")
# Resolve entities
resolved_entities = []
if found_entities:
for entity in found_entities:
resolved_entity = resolve_entity(entity, COUNTRY_NAME_MAP)
if resolved_entity:
resolved_entities.append(resolved_entity)
with open(output_metadata_json_path, "w") as out_f:
print(f"Writing metadata to {output_metadata_json_path}")
out_f.write(
json.dumps(
{
"found_entities": found_entities,
"resolved_entities": resolved_entities,
}
)
)This function reads the text extract of a comment and using the wonderful huspacy library extracts LOC type entities using these few lines:
def find_entities_huspacy(text):
nlp = huspacy.load()
doc = nlp(text)
entities = [ent.text for ent in doc.ents if ent.label_ == "LOC"]
return entitiesAs an example, the following comment will result in the entities found below it:
Lehet a korod, vegzettseged miatt neked jobb lenne megcelozni Ausztraliat vagy Uj Zelandot. Kedvezö szamodra a pontrendszer a bevandorlashoz.
Nezzel ra!{
"found_entities": [
"Ausztraliat",
"Uj Zelandot"
],
"resolved_entities": [
"Australia",
"New Zealand"
]
}found_entities are the raw LOC entities that huspacy grabbed for us from the text and resolved_entities contain the properly formatted, English version of the country names.
Standardizing the data is important because we want to easily aggregate downstream without having to do any manual data cleaning.
Aggregate!
Great, the hard part is done (why is getting and cleaning the data always the hard part?!). All that's left to do is read the resolved entities and merge them into one big dataset.
This can be easily done with a few lines of Python as well. We'll pull in old trustworthy pandas to help us out.
def merge_metadata():
metadata_files = glob.glob(
"./data/escapehungary/comments/**/*.json", recursive=True
)
all_countries = set()
metadatas = defaultdict(set)
for metadata_file in metadata_files:
with open(metadata_file, "r") as f:
comment_date = os.path.basename(os.path.dirname(metadata_file))
metadata_json = json.load(f)
if "resolved_entities" not in metadata_json:
continue
for entity in metadata_json["resolved_entities"]:
all_countries.add(entity)
metadatas[comment_date].update(metadata_json["resolved_entities"])
# Create a dataframe matrix where the rows are the dates and
# the columns are the country names
# and the values are the number of comments mentioning the country on that day
df = pd.DataFrame(0, index=sorted(metadatas.keys()), columns=sorted(all_countries))
for date, countries in metadatas.items():
for country in countries:
df.loc[date, country] += 1
df = df.sort_index()
df = df.reset_index()
df = df.rename(columns={"index": "date"})
df.to_csv(
"./data/escapehungary/escapehungary_metadata.csv",
quoting=csv.QUOTE_ALL,
index=False,
)After running these lines we'll get an output table like this:
| date | Afghanistan | ... | Vietnam | Yemen |
|---|---|---|---|---|
| 2022-04-04 | 0 | ... | 0 | 0 |
| 2022-04-05 | 0 | ... | 0 | 0 |
| 2022-04-06 | 0 | ... | 0 | 0 |
Nice! Looks like nobody is talking about Afghanistan, Vietnam, and Yemen, huh?
Also, I only chose this sparse matrix format to make it easier to aggregate the data later.
Analytics
Alright, let's get into hardcore analytics! Just kidding, for the sake of this exploration to keep it short we'll only calculate that one initial metric we were talking about.
Because of the format we chose to store the data, getting the list of most mentioned countries is as simple as:
top_countries = df.sum().sort_values(ascending=False).head(50)This creates a series that holds the top 50 mentioned countries, which should be enough for our final visualization! I won't post how the results look to avoid spoilers.
To visualize the results, I opted to try out Sigma, which proved very easy to use!
So, without further ado - the results!
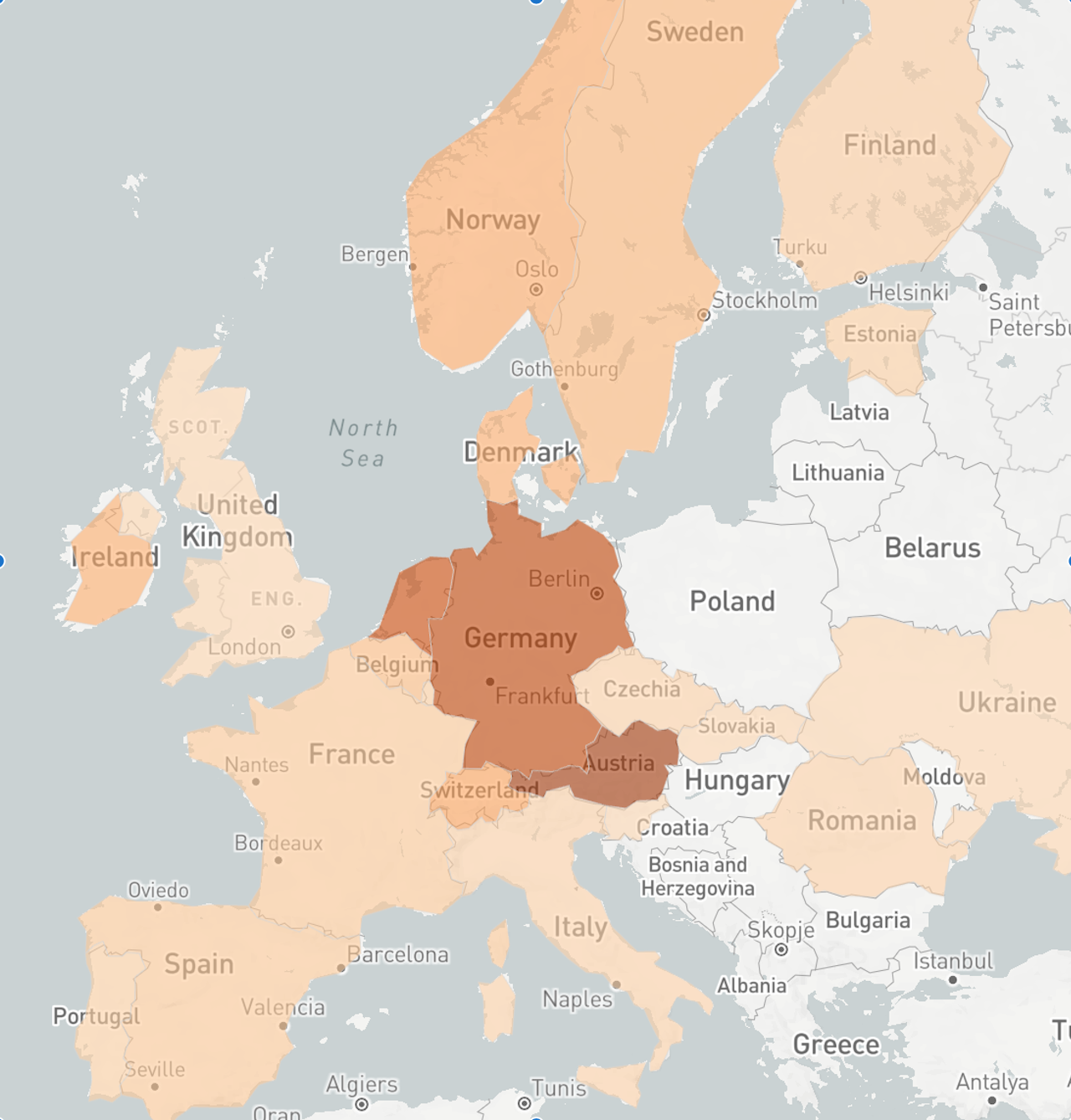
And in raw numbers, the top 10:
| country | count |
|---|---|
| Austria | 66 |
| Germany | 58 |
| Netherlands | 55 |
| Canada | 27 |
| England | 26 |
| Australia | 22 |
| Switzerland | 22 |
| Norway | 19 |
| Ireland | 18 |
| Denmark | 18 |
Surprising? For the Hungarian readers, probably not.
Conclusion
There are a lot of issues with this analytics, mainly that it starts by extracting only country names – there are lots of mentions of cities as well, it would be nice to do a lookup of those to match to certain countries (this is way above my knowledge in Hungarian NLP) and it also should be combined with some form of sentiment analysis as these mentions could occur in a negative tone, although rarely.
Member discussion