Apple Airtag location history — data pipeline & dog tracking dashboard
Episode n+1 of using overkill tech to build simple data pipelines in order to learn about how they work.
While you can use the official Find My app on your Mac to track your Apple devices sadly (or not — for privacy reasons) it doesn’t keep any location history which makes it hard to trace routes in order to see where your precious devices might have gone / be going.
In particular I was interested in the path of my dog, Misha, on off-leash walks and hikes.

As usual — all the code used in this project can be found on GitHub: https://github.com/danthelion/airtag-locator
E(xtract)
To build a dashboard where I can draw the route Misha took first I need to get the data from the Airtag. The only possible way I found to do this was to extract it from the Find My apps cache, located at {HOME}/Library/Caches/com.apple.findmy.fmipcore/Items.data .
This cache is a json file which contains all kinds of metadata about tracked devices. But for now we are only interested in the location properties; latitude and longitude.
To extract these fields on a scheduled basis I wrapped the logic in a Meltano pipeline to simplify the whole process.
A Meltano pipeline starts with a Tap, based on the Open Source Singer.io specification. There are hundreds of already existing taps for different data sources but there wasn’t one for the Find My cache so I had to write my own.
The main component for this — the Stream class — defines the schema of the incoming data.
L(oad)
As our target “data warehouse” I will use PostgreSQL now and it’s fairly easy to set up and works perfectly for home-lab/demonstration type environments.
Meltano handles all the type conversions and loading logic required. Our main configuration looks like this so far. We are using the custom tap-findmy as an extractor and an existing loader called pipelinewise-target-postgres to load the data into our database.
At this point we are able to run our pipeline as such.
meltano elt tap-findmy target-postgres
This will read the data from the cache, parse it, load it into Postgres and save the state to a local file so we can do incremental loads in the future. Great!
T(ransform)
So far our raw data coming from Find My looks like this in Postgres.

As a next step I would like to clean it up a bit and create a view that filters data for the past day only.
For this I can utilizedbt fairly easily thanks to its integration with Meltano.
Our “staging” model, where we flatten the structure a bit, fix the types and the field names looks like this:
And for “reporting” on daily movement this is the model we will use.
After running the models, our reporting table in Postgres will look like this, ready to be visualized on a map!

ELT
But first, I’d like to wire all of these steps together to easily automate it to run in the background and collect location data for me.
To do this I extend our initial Meltano configuration with a job definition.
I can create a job definiton with the following command
meltano job add load-item-location-from-cache --tasks "tap-findmy target-postgres sqlfluff:lint dbt-postgres:item"
And this will generate the jobs entry in our configuration.jobs:
- name: load-item-location-from-cache
tasks:
- tap-findmy
- target-postgres
- sqlfluff:lint
- dbt-postgres:item
This wraps all the individual commands into one named job, so I can just run
meltano run load-item-location-from-cache
And all the tasks you see in the definiton will be chained together and ran in a nice pipeline. (I also included an sqlfluff linting step to help me beautify my dbt models — this is completely optional)
To schedule this pipeline to run every 5 minutes for example in the same vein I can create a schedule entry in the configuration with
meltano schedule add daily-findmy-load — job load-item-location-from-cache — interval ‘@daily’
meltano schedule add findmy-items-5m --job load-item-location-from-cache --interval "* /5 * * *"
And the respective configuration generated is.schedules:
- name: daily-findmy-load
interval: '@daily'
job: load-item-location-from-cache
To run the actual orchestration I used the builtin support for Airflow, which generates dags based on the Meltano job definitions.
Visualization
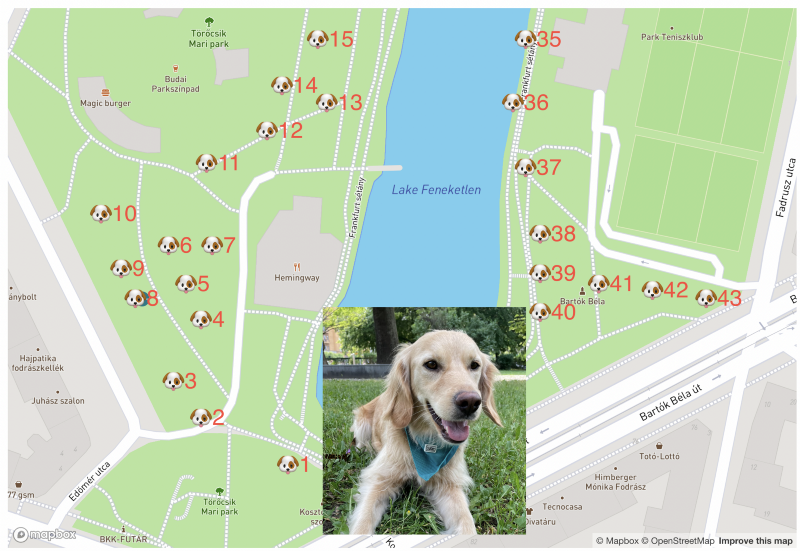
Now that everything is in place in the backend to gather the data automatically we can work on visualizing it. I’ll be using Superset and after adding it to our Meltano project as a utility with meltano add utility superset .
To start the Superset UI simply call meltano invoke superset:ui . After fiddling with Superset for hours I gave up on trying to draw a line between the coordinates and just went with numbering them. If you choose a better visualization tool there has to be a nicer way than this.
Conclusion
Meltano is a great tool for robust data pipelines with a great number of integrations and the Singer spec is a good tool to quickly write ingestions. I can recommend it even for hobby projects!
Sadly there is no open API to connect to Find My or Airtags at all so for this whole thing you will need a constantly running Mac that has Find My open in order to update the cache regularly.
Member discussion