Kafka Consumer Groups

Distributed data processing has become increasingly common in modern software applications. As data grows in volume and complexity, it becomes more difficult for a single machine to process it all in a reasonable amount of time. To handle these challenges, many applications use distributed data processing frameworks like Apache Kafka.
Kafka is a distributed streaming platform that allows applications to publish and consume data streams in real time. It is designed to handle large volumes of data and provide reliable, fault-tolerant data processing. However, working with distributed data processing introduces new challenges, including how to coordinate and manage multiple consumers that are reading data from the same Kafka topic.
This is where Kafka consumer groups come in. A consumer group is a set of consumers that jointly read from a single Kafka topic. Each message that is published to the topic is delivered to only one member of the group, ensuring that each message is processed by only one consumer. This allows multiple consumers to work together to process large volumes of data more efficiently.
In this article, we'll dive into the details of how Kafka consumer groups work and explore best practices for using them effectively. Whether you're a software developer working with Kafka or an IT professional responsible for managing Kafka clusters, understanding consumer groups is essential for building robust, scalable data processing pipelines.
How Kafka Consumer Groups Work
At a high level, a Kafka consumer group is a set of consumers that are subscribed to a single Kafka topic. When messages are published to the topic, they are delivered to only one member of the group. This allows multiple consumers to work together to process large volumes of data more efficiently.
In essence, setting up consumer groups is a way of parallelizing workloads on the consumer side.
In the simplest example, let's image a Kafka pipeline that has 1 topic, called user_logins where we record login events of users in our application. These events get consumed by a service whose only job is to count them.
The simplest way to create this is if we define our topic to have a partition count of 0, this way all incoming records will land in that one partition, and our consumer "group" will only consist of one consumer.
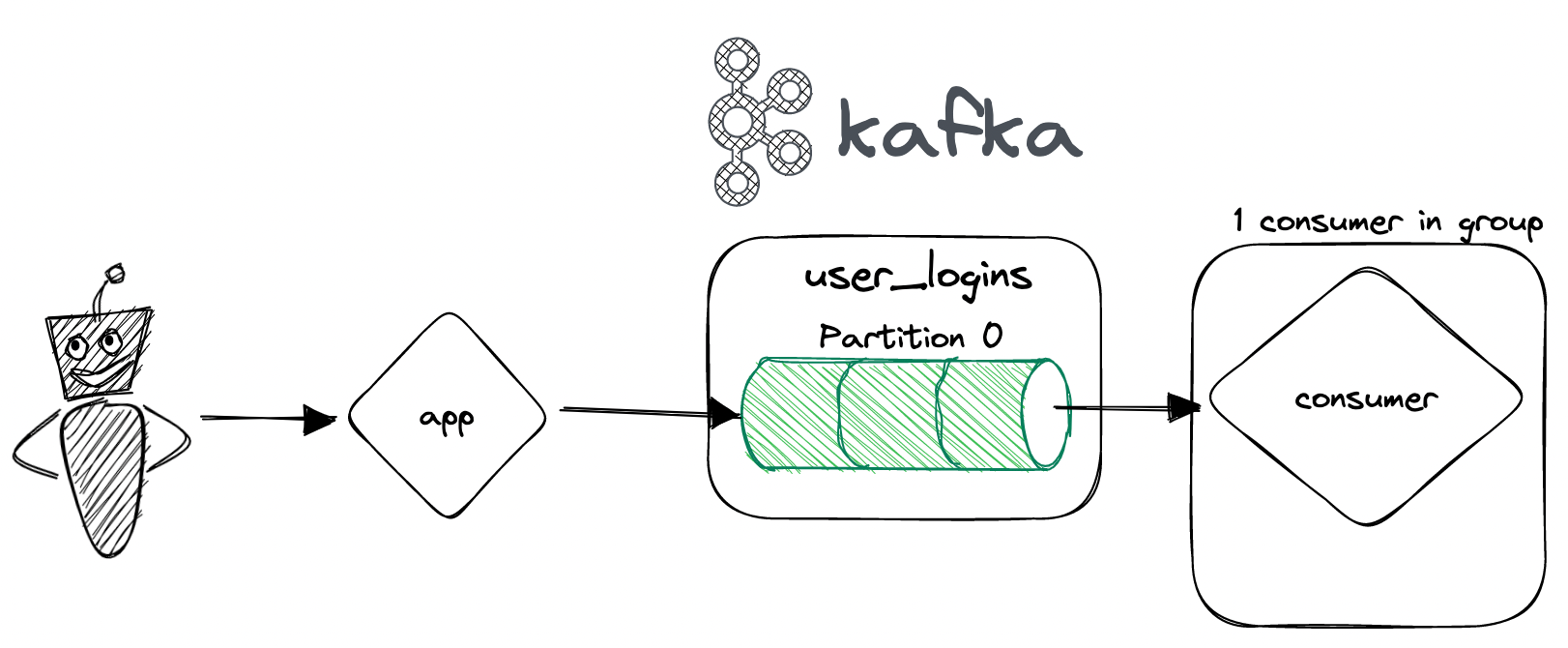
This is great and it works, but one partition will not be enough if we start to scale our application and the number of logins will increase exponentially!
Kafka Partitions and Consumer Group Assignment
To understand how Kafka consumer groups work, it's crucial to understand Kafka partitions. A Kafka topic can be divided into one or more partitions, which are separate and independent streams of data. Each partition can be read by only one consumer at a time. If you have more consumers than partitions, some consumers will be idle and not receive any data.
When you create a Kafka consumer group, you specify a group ID. All consumers that belong to the same group have the same group ID. When a new consumer joins a group, Kafka assigns it to a subset of the partitions for the subscribed topic. If a consumer leaves the group, the remaining consumers in the group are reassigned to the available partitions.
So, if we extend our previous example with more partitions and more consumers, we get something like this:
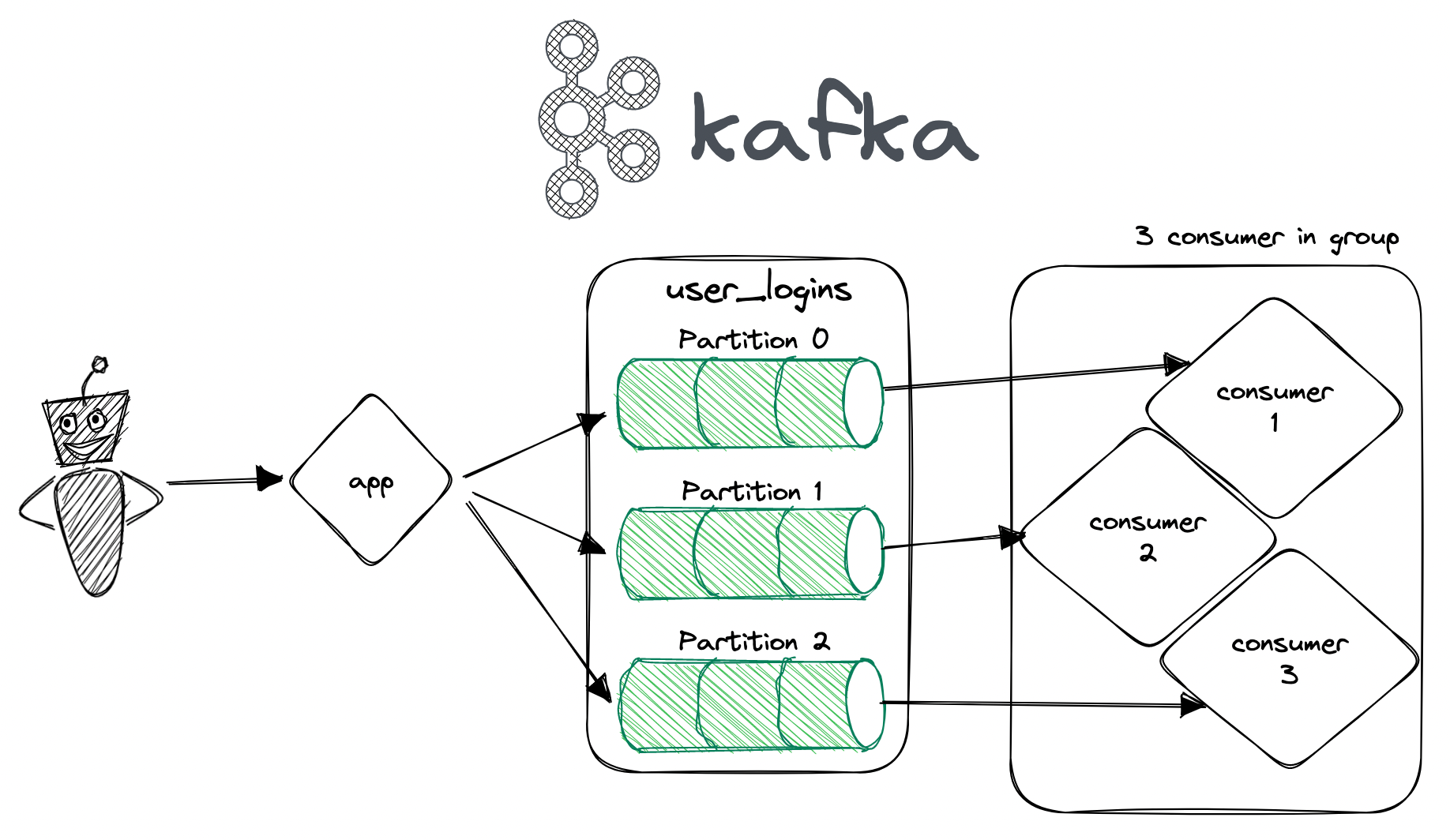
This way, we greatly increase the performance of both the producer side AND the consumer side as we are able to process three partitions in parallel!
What happens if we have one consumer but multiple partitions to consume from?
If you have one consumer for multiple partitions, that consumer will be responsible for processing all messages from all partitions it is assigned to. This means that the consumer will receive messages from multiple partitions interleaved together, and it will be up to the consumer to maintain ordering if necessary.
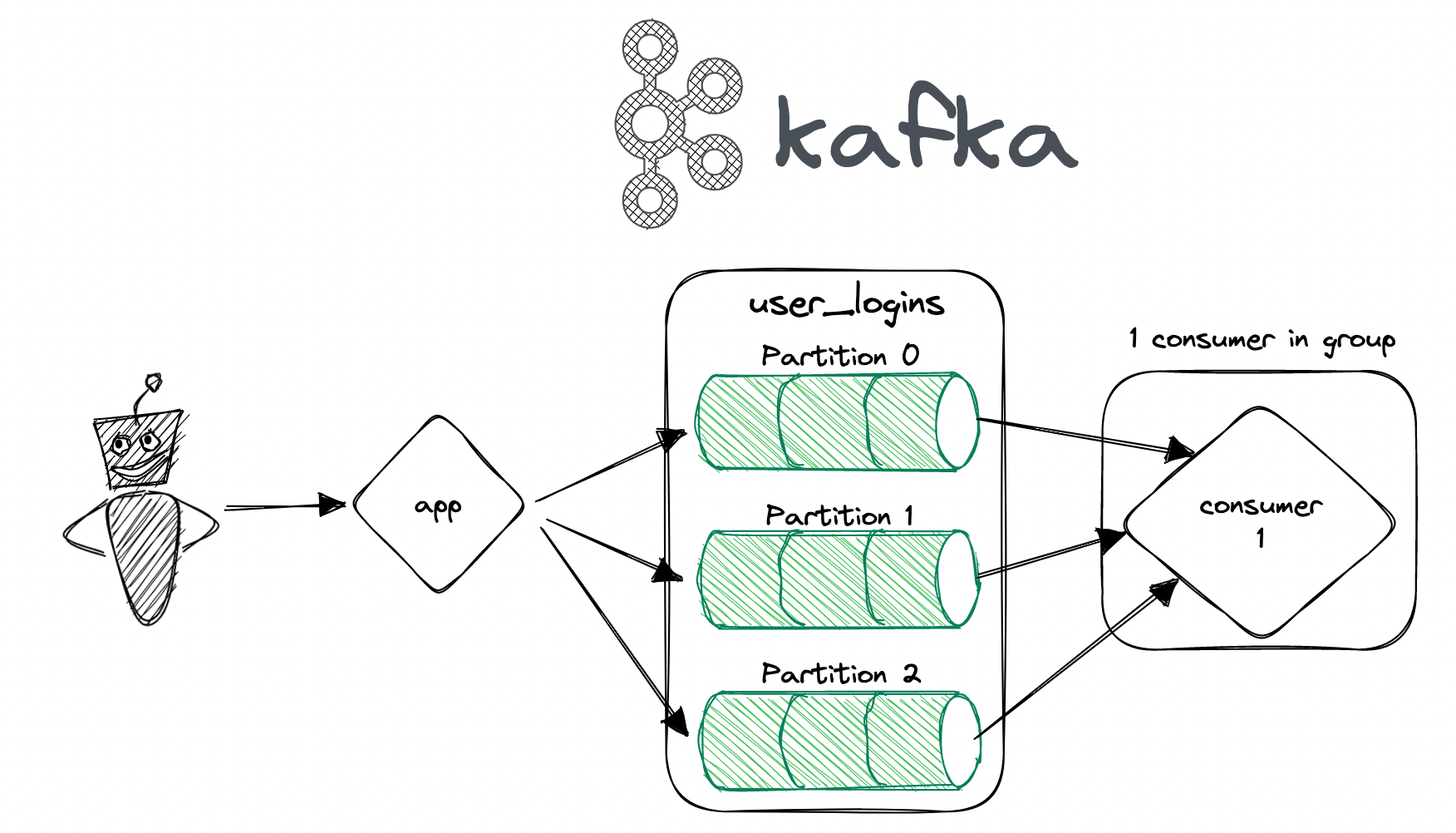
For example, if you have a topic with three partitions and a single consumer assigned to all three partitions, the consumer might receive messages in the following order:
Partition 0: message1, message2, message3, message4
Partition 1: message5, message6, message7
Partition 2: message8, message9, message10, message11, message12As you can see, the messages from each partition are interleaved together, and the consumer must process them in the correct order if message order matters for your application.
When you have a single consumer processing multiple partitions, you should be aware that the consumer will only be able to process as many messages as its processing capacity allows. If the consumer is not able to keep up with the incoming messages from all partitions, the partitions with the most messages may start to lag behind, which can cause problems if you need to maintain strict message ordering. In this case, you may need to add more consumers to the consumer group to handle the load or consider scaling up your consumer instances to handle the increased traffic.
Can multiple consumer groups consume the same topic?
Yes, multiple consumer groups can consume from the same topic in Kafka. Each consumer group maintains its own offset per partition, so each group will read the topic independently of the other groups. This means that multiple consumer groups can process the same messages from the same topic at the same time.
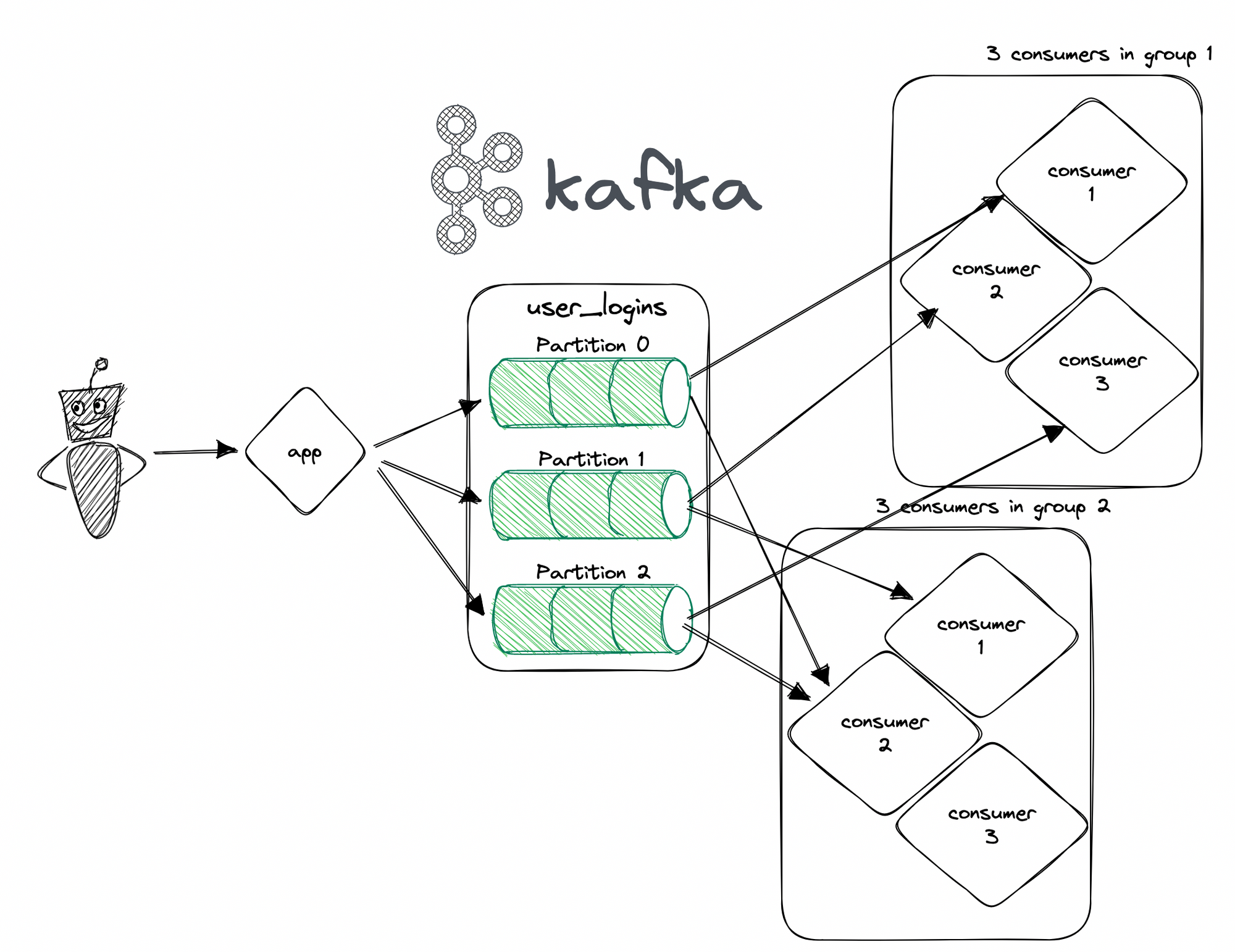
For example, if you have a topic with three partitions and two consumer groups, each group might receive messages in the following order:
Consumer group 1:
Partition 0: message1, message4
Partition 1: message5, message8
Partition 2: message10, message12Consumer group 2:
Partition 0: message2, message3, message6
Partition 1: message7, message9
Partition 2: message11As you can see, each consumer group is processing messages from the topic independently of the other group. This can be useful in situations where you need to process the same messages in different ways or with different levels of parallelism.
Consumer Group Rebalancing
Consumer group rebalancing is the process of redistributing partitions among the members of a consumer group. It happens automatically whenever a new consumer joins or leaves the group. During rebalancing, Kafka ensures that each partition is assigned to only one consumer at a time.
Rebalancing can cause temporary disruptions in data processing, since consumers may need to stop processing messages while the group is being rebalanced. To minimize disruptions, it's important to choose an appropriate partition assignment strategy and tune consumer group configuration settings.
In the next section, we'll explore how to use Kafka consumer groups in practice and provide recommendations for how to configure them effectively.
How to Use Kafka Consumer Groups
Now that we've explored how Kafka consumer groups work, let's take a look at how to use them in practice.
Creating a Kafka Consumer Group
To create a consumer group, you'll need to specify a group ID when you create a Kafka consumer. All consumers that belong to the same group have the same group ID. Here's an example of how to create a consumer group in Python using the kafka-python library.
from kafka import KafkaConsumer
consumer = KafkaConsumer(
'user_logins',
group_id='user_logins_counter',
bootstrap_servers=['localhost:9092']
)In this example, we've created a consumer group with the group ID my-consumer-group. The bootstrap.servers configuration option specifies the Kafka broker addresses that the consumer should use to connect to the Kafka cluster. The consumer group currently only has one consumer (the one we just created) and is subscribed to the user_logins topic.
Consuming Messages with a Consumer Group
Once you've created a consumer group, you can use it to consume messages from a Kafka topic. Here's an example of how to consume messages with a consumer group in Python:
logins = 0
for message in consumer:
record = message.value.decode("utf-8")
print(f'Received message: {record}')
if record["status"] == "success":
logins += 1In this example, we're using a for loop to continuously poll for new messages. If the status of the login was deemed successful, we increment our logins counter. Doesn't get simpler than this!
Now let's say we increase the user_logins topics partition count to 3, as in our first example – this means we can also start adding more consumers!
from kafka import KafkaConsumer, TopicPartition
# Set up consumer configuration
consumer_config = {
'bootstrap_servers': ['localhost:9092'],
'group_id': 'user_logins_counters',
'auto_offset_reset': 'earliest',
'enable_auto_commit': False
}
# Create three consumers in the same group
consumer1 = KafkaConsumer('user_logins', **consumer_config)
consumer2 = KafkaConsumer('user_logins', **consumer_config)
consumer3 = KafkaConsumer('user_logins', **consumer_config)
logins = 0
def process_message(msg):
record = message.value.decode("utf-8")
if record["status"] == "success":
logins += 1
# Start processing messages
while True:
# Poll for new messages
msg_batch1 = consumer1.poll(timeout_ms=1000, max_records=10)
msg_batch2 = consumer2.poll(timeout_ms=1000, max_records=10)
msg_batch3 = consumer3.poll(timeout_ms=1000, max_records=10)
# Merge message batches from all consumers
merged_msg_batch = {}
for msg_batch in [msg_batch1, msg_batch2, msg_batch3]:
for tp, msgs in msg_batch.items():
if tp not in merged_msg_batch:
merged_msg_batch[tp] = []
merged_msg_batch[tp].extend(msgs)
# Process messages
for tp, msgs in merged_msg_batch.items():
for msg in msgs:
process_message(msg)
# Commit offsets
consumer1.commit()
consumer2.commit()
consumer3.commit()Keep in mind, this example is more contrived than it is needed to be, usually, there is only 1 consumer per process – but for the sake of showcasing how they function, I tried to cram them into one snippet.
In this updated example, we poll for messages from all three consumers during each iteration of the loop. We then merge the message batches from each consumer into a single batch that contains messages from all partitions. This allows us to process messages from all consumers in a single pass through the batch, which can improve performance.
Note that the order in which messages are processed is not guaranteed to be the same as the order in which they were produced to the topic, since each consumer is processing messages independently. However, Kafka guarantees that messages within a partition will be processed in order. So if your application requires strict ordering guarantees, you should use a single consumer per partition.
Best Practices for Using Kafka Consumer Groups
When using Kafka consumer groups, it's important to follow best practices to ensure that your application runs smoothly and efficiently. Here are some tips to help you get the most out of Kafka consumer groups:
Use a Consistent Group ID
When creating a consumer group, use a consistent group ID for all consumers that belong to the same group. If you use different group IDs for different consumers, Kafka will treat them as separate consumer groups, which may cause unexpected behavior.
Tune Consumer Group Configuration Settings
Kafka consumer groups offer a variety of configuration options that you can use to fine-tune their behavior. Some of the most important configuration options include:
group_id: The ID of the consumer groupauto_offset_reset: What to do when there is no initial offset in Kafka or if the current offset does not exist anymore on the serverenable_auto_commit: Whether or not to automatically commit offsets after processing messagesmax_poll_records: The maximum number of records returned in a single pollmax_poll_interval_ms: The maximum amount of time between poll requests
It's important to tune these settings appropriately for your use case to ensure that your consumers are processing messages efficiently and effectively.
Choose an Appropriate Partition Assignment Strategy
Kafka offers several partition assignment strategies that you can use to determine how partitions are assigned to consumers in a consumer group. The default strategy is RangeAssignor, which assigns contiguous ranges of partitions to consumers. However, depending on your use case, you may want to consider using a different assignment strategy, such as RoundRobinAssignor or StickyAssignor.
Handle Consumer Group Rebalancing Carefully
Consumer group rebalancing can cause temporary disruptions in data processing, since consumers may need to stop processing messages while the group is being rebalanced. To minimize disruptions, it's important to choose an appropriate partition assignment strategy and tune consumer group configuration settings.
You should also handle consumer group rebalancing carefully in your application code. For example, you may want to commit offsets manually before a rebalance to ensure that you don't lose any processed messages.
Monitor Consumer Lag
Consumer lag refers to the delay between when a message is produced and when it is consumed by a consumer in the group. Monitoring consumer lag can help you identify performance issues and bottlenecks in your application.
You can monitor consumer lag using tools like the Kafka consumer group command-line tool (bin/kafka-consumer-groups.sh) or a monitoring system like Prometheus. If you notice high levels of lag, you may need to tune your consumer group configuration settings or scale up your application to handle the increased load.
Conclusion
Kafka consumer groups are a powerful tool for processing large volumes of data in real time. By creating a group of consumers that work together to process messages, you can achieve high levels of throughput and scalability. However, it's important to follow best practices and tune your consumer group configuration settings appropriately to ensure that your application runs smoothly and efficiently.
Member discussion