Redpanda ✕ Materialize ✕ dbt ✕ Debezium
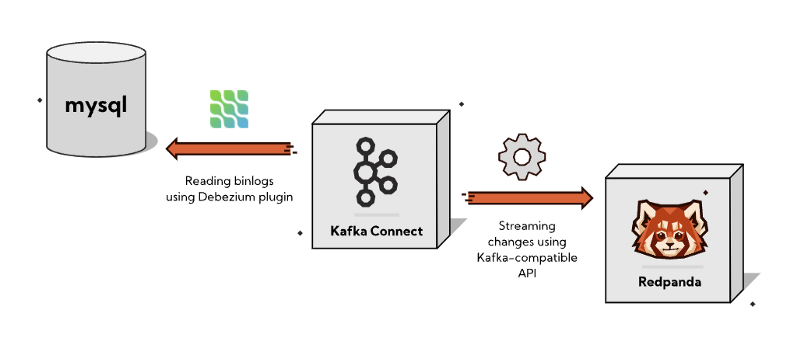
After attending the recent Hack Day held by the Materialize team I’ve decided to experiment with their product by creating a CDC pipeline which streams change events from a MySQL databases binlog through Debezium into Redpanda where via dbt we can define our live materialized views which feed a Metabase dashboard.
If that sounds like a lot weird words, it’s because it is. Let’s unpack these technologies and our pipeline step by step.
The code for the example can be found here: https://github.com/danthelion/redpanda-debezium-materialized-dbt
Data ingestion
- MySQL — Our source Database.
- Redpanda —A new storage engine, optimized for streaming data.
- Kafka Connect — component of Apache Kafka that works as a centralized data hub for simple data integration between databases, key-value stores, search indexes, and file systems.
- Debezium —An open source distributed platform for change data capture.
What is CDC and why is it useful?
Change Data Capture (CDC) is the ideal solution for real-time (or close to it) data streaming from relational DBs (MySQL, PostgreSQL, …) into Data Warehouses (BigQuery, Snowflake, …).
In this example we are going to connect to our MySQL databases binary log (binlog) which captures all operations in order in which they are commited to the database. This includes changes to table schemas as well as changes to the data in tables. MySQL uses the binlog for replication and recovery.
The Debezium MySQL connector reads the binlog, produces change events for row-level INSERT, UPDATE, and DELETE operations, and emits the change events to Kafka topics.
Due to Redpanda having a fully compatible Kafka API (and being a lot easier to get started with), we are able to leverage the Connect image provided by Confluent.
The relevant part in our docker-compose.yml looks like this:debezium:
image: debezium/connect
depends_on:
- redpanda
- mysql
ports:
- "8083:8083"
environment:
BOOTSTRAP_SERVERS: "redpanda:9092"
GROUP_ID: "1"
CONFIG_STORAGE_TOPIC: "inventory.configs"
OFFSET_STORAGE_TOPIC: "inventory.offset"
STATUS_STORAGE_TOPIC: "inventory.status"
KEY_CONVERTER: io.confluent.connect.avro.AvroConverter
VALUE_CONVERTER: io.confluent.connect.avro.AvroConverter
CONNECT_KEY_CONVERTER_SCHEMA_REGISTRY_URL: http://redpanda:8081
CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL: http://redpanda:8081
mysql:
image: debezium/example-mysql:1.6
ports:
- "3306:3306"
environment:
MYSQL_ROOT_PASSWORD: debezium
MYSQL_USER: mysqluser
MYSQL_PASSWORD: mysqlpw
redpanda:
image: docker.vectorized.io/vectorized/redpanda:v21.11.3
container_name: redpanda
command:
- redpanda start
- --overprovisioned
- --smp 1
- --memory 1G
- --reserve-memory 0M
- --node-id 0
- --check=false
- --kafka-addr 0.0.0.0:9092
- --advertise-kafka-addr redpanda:9092
- --pandaproxy-addr 0.0.0.0:8082
- --advertise-pandaproxy-addr redpanda:8082
- --set redpanda.enable_transactions=true
- --set redpanda.enable_idempotence=true
- --set redpanda.auto_create_topics_enabled=true
ports:
- "9092:9092"
- "8081:8081"
- "8082:8082"
healthcheck: { test: curl -f localhost:9644/v1/status/ready, interval: 1s, start_period: 30s }
These services are enough to create the basis of our CDC pipeline.
After starting the ingestion services, you can create the Debezium source connector with a simple call the the connectors API:❯ curl --request POST \
--url http://localhost:8083/connectors \
--header 'Content-Type: application/json' \
--data @debezium/mysql-source.json
The interesting part is the second half, where we define our materialized views which, due to Materialize, are live without any human interaction and they are kept updated whenever the underlying data (in our case in Redpanda) is updated.
Frick it, we’ll do it live 😤
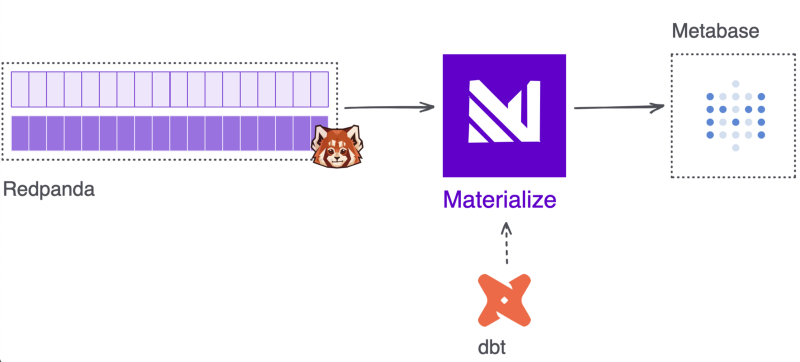
- Materialize — SQL streaming database.
- dbt — A data transformation tool that enables data analysts and engineers to transform, test and document data in the cloud data warehouse.
- Metabase — An open source Business Intelligence server.
In a little bit more detail about these services and their role in our example:
Materialize
Materialize is set up to consume streaming sample customer information from Redpanda. Any sources and transformations are defined through dbt!
mzcli
A psql-like SQL client, so you can easily connect to the running Materialize instance, but if you have a postgres client installed on your localed development machine, you can omit this service.
dbt
dbt acts as the SQL transformation layer. Using the dbt-materialize adapter, you can build and run models to transform the streaming source data in real time.
Metabase
One of the ways to get data out of Materialize is through visualizing it. In this example I used Metabase to query data from the materialized views in order to explore the dataset in real time.
These services are defined as follows: materialized:
image: materialize/materialized:v0.20.0
container_name: materialized
command: -w1
ports:
- "6875:6875"
mzcli:
image: materialize/cli
container_name: mzcli
dbt:
build:
context: ./dbt
target: dbt-third-party
args:
- build_for=${ARCH}
container_name: dbt
ports:
- "8000:8080"
volumes:
- ./dbt/profiles.yml:/root/.dbt/profiles.yml
- ./dbt/:/usr/app/dbt
stdin_open: true
tty: true
depends_on:
- materialized
metabase:
image: ${MIMG}/metabase
container_name: metabase
depends_on:
- materialized
ports:
- "3030:3000"
Up & Running
After you brought up all the services using docker-compose up -d , the next step is to run our dbt models.
Our models are organized in the following structure:❯ tree
.
├── marts
│ └── inventory
│ ├── fct_inventory.sql
│ └── fct_inventory.yml
├── sources
│ └── inventory
│ ├── inventory_customers.sql
│ └── src_inventory.yml
└── staging
└── inventory
├── stg_inventory.yml
└── stg_inventory_customers.sql
The source definition under sources/inventory/inventory_customers.sql is where we tell Materialize to connect to Redpanda and unwrap the Debezium Envelope which contains all the metadata about our CDC events.CREATE SOURCE {{ source_name }}
FROM KAFKA BROKER 'redpanda:9092' TOPIC 'dbserver1.inventory.customers'
FORMAT AVRO USING CONFLUENT SCHEMA REGISTRY 'http://redpanda:8081'
ENVELOPE DEBEZIUM;
The actual evens contain both before and after states of a record and some extra metadata about the transaction but for our case we can just opt to unwrap it before using them in the staging view.
An alternative would be to feed the wrapped events into a view and create our own SCD2 history views based on that so we can look back in history as needed.
The staging view in this example (staging/inventory/stg_inventory_customers.yml ) doesn’t contain any useful code as the source is already in a usable state, but this would be the place to convert data from JSON and fix types for example; if your source would be in JSON format pushed into Redpanda.
Because we use the integrated Schema Registry of Redpanda and our CDC events have a nice AVRO schema attached to them, we don’t have to care about type conversions here.
Running the models can be achieved by entering the dbt container,docker exec -it dbt /bin/bash
and then we can just run our models as usual.dbt depsdbt run
To inspect our Materialize database we’ll start the mzcli servicedocker-compose run mzcli
Similarly you could connect via psql.
psql -U materialize -h localhost -p 6875 -d materializeTo get a quick overview of what is inside our database we can use some built in commandsSHOW SOURCES;
name
-----------------------
inventory_customersSHOW VIEWS;
name
------------------------
fct_inventory
stg_inventory_customers
Try running a query against fct_inventory, this is our materialized view which holds our live data.
The last step in our little adventure would be to head over to http://localhost:3030 and set up a connection to our Materialize database.
Database: PostgreSQL
Name: inventory
Host: materialized
Port: 6875
Database name: materialize
Database username: materialize
Database password: Leave empty
Feel free to validate the freshness of our materialized view by adding a new record, updating one or deleting some in the source MySQL database.
Conclusion
The modern data stack provides us an amazingly fast getting-started experience compared to previous generations.
Setting up Redpanda is so easy compared to a Kafka cluster I spent around 30 minutes trying to find errors in my local deployment even though everything was already working.
Materialize is an amazing tool if you need live data. This small example doesn’t even begin to scratch the surface of what’s possible with it currently, and what will be in the future. Definitely worth to keep an eye on their progress.
The integration with dbt makes it easy to keep track of our view definitons and even though their live nature makes the usual scheduled dbt runs obsolete, it still provides amazing value through testing, documentation and other features that it is definitely worth to keep in our stack.
Member discussion